



[🍋DataSource란?]
DataSource가 없을땐 JDBC를 사용하며 DB에 접근할 때 마다
Connection이라는 것을 얻어야 했다.
이 Connection을 열고 끊고를 반복해서 사용해야 하는데
이 Connection 열고 끊는 작업의 횟수를 줄이기 위해
DataSource 미리 Connection을 생성한다.
이렇듯 커넥션들을 생성하고 관리를 할 수 있는 것이 바로 DataSource이다.
이 DataSource는 또한 Connection을 관리하거나 모아놓은 수도 있는데
이것은 Connection Pool이라고 한다.
[🍎Connection이란?]
그렇다면 Connection이라는 것을 무엇일까?
우리는 DB에 접근하기 위해서는 4가지의 정보를 알아야만 한다.
▶ DB Driver
▶ DB URL
▶ DB UserName
▶ DB PassWord
이 네 가지의 정보를 DataSource에 넣어준다면 DB에 getConnection의 메서드를 통해
Connection의 정보를 준다. 이것이 DB에 연결 할 수 있는 입장권이라고 생각하면 쉽다.
즉 이 Connection은 DB의 접근할 수 있는 입장권이며 이 입장권이 있어야만
DB에 접근 할 수 있는 것 이다.
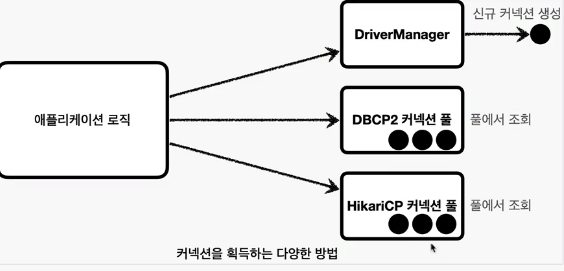
이 Connection을 얻는 방법은 다양하지만 이번은 DataSource에서 알아보도록 하자.
[🍌Connection Pool이란?]
그렇다면 이 Connection Pool 이라는 것은 무엇일까?
Connection이 입장권이라고 얘기했다.
그렇다면 이 Connection들을 모아놓은 곳 들이 바로 Connection Pool이라 할 수 있겠다.
기본적으로 Connection은 DB에 접근하면 열고 DB의 종료가 끊난다면 Connection을 끊고
열고 끊고 작업을 반복한다. 그렇게 된다면 DB의 접근하는 시간이 많이 들기 때문에
사용자 입장에서는 불편함을 느낄 수 있게 된다.
이러한 현상을 없애기 위해서 각 DB의 일정량의 Connection을 만들어 놓고
Connection Pool에 대기 시켜놓는 것 이다.
예를들어 생각 해보자.
나는 웹 어플리케이션을 열었고 사용자가 1명이 들어왔다. Connection은 1개가 있다.
이럴 경우 사용자가 1명이기 때문에 1개의 Connection을 만들어 사용하고 종료하면 문제가 없다.
하지만 사용자가 10명이 들어왔을 경우 10명의 사용자가 DB의 접근을 하고 싶어한다.
하지만 Connection은 1개 밖에 없기 때문에
9명의 사용자 들에게 Connection을 9개를 만들어 줘야 한다.
하지만 Connection은 만드는 과정도 복잡할 뿐더러 커넥션을 획득할때도 많은 절차가 있다.
그렇기 때문에 사용자는 Connection을 획득할 때 불편함을 겪게 될 것 이다.
이러한 현상을 방지 하기 위해 Connection을 미리 만들어 놓고
Connection Pool의 Connection을 대기 시켜놓는 것 이다.
Connection을 10개를 만들어 놓는다면 10명의 사용자가 들어와서 DB의 연결을 하고 싶다해도
Connection이 10개가 있기 때문에 원활하게 사용자와 연결 할 수 있는 것 이다.
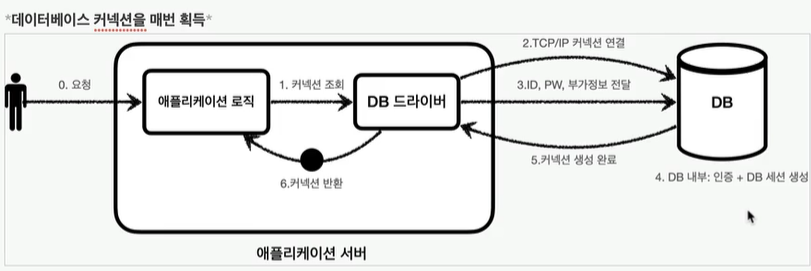
이렇듯 한개의 커넥션을 얻기 위해선 이렇게 수 많은 과정들을 거쳐야 한다.

이렇듯 커넥션 풀에 있는 커넥션은 DB와의 연결이 되어있는 상태이기 때문에 언제든지 SQL을 보낸다면
DB에 메세지를 전달 할 수 있다.
[🍊 DataSource Hikari]
자바는 기본적으로 DataSource 인터페이스를 사용하여 커넥션 풀을 관리한다.
spring Boot 2.0 이전에는 커넥션 풀을 관리하는 tomcat-jdbc를 사용하였지만
2.0 이후부터는 커넥션 풀을 관리하는 hikari cp가 기본옵션으로 채택되고 있다.
그렇기 때문에 자바에서 제공하는 기본적인 DataSource는 hikariCP로 사용되고 있다
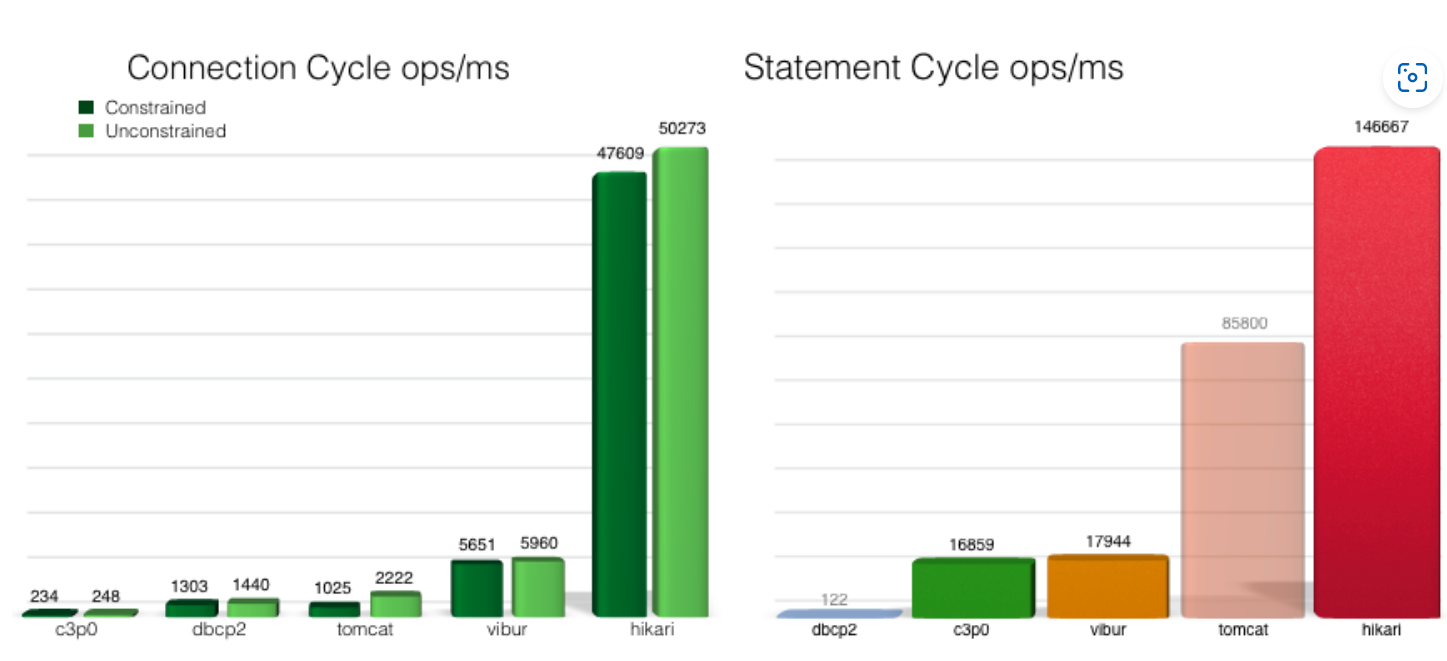
이렇듯 hikariCp가 다른 커넥션 풀 관리 시스템 보다 월등한 성능을 보여준다.
[🍓스프링의 DataSource 사용]
그렇다면 이 DataSource라는 것을 알았으니 스프링에서의 사용을 해보도록 하자.

DataSource를 사용하기 위해서는 hikariDataSource를 얻어야만 한다.
얻는 방법은
HikariDataSource hikariDataSource = new HikariDataSource();
이렇게 hikariDataSource를 생성해 얻으면 된다.
얻은 후 위에서 말했듯이 DB 커넥션을 얻기 위해선
네 가지의 조건이 필요하다고 했다.
▶ DB Driver
▶ DB URL
▶ DB UserName
▶ DB PassWord
hikariDataSource.setJdbcUrl(URL);
hikariDataSource.setUsername(USERNAME);
hikariDataSource.setPassword(PASSWORD);
그렇기 때문에 DB의 url과 userName , PassWord를 입력해주면 된다.
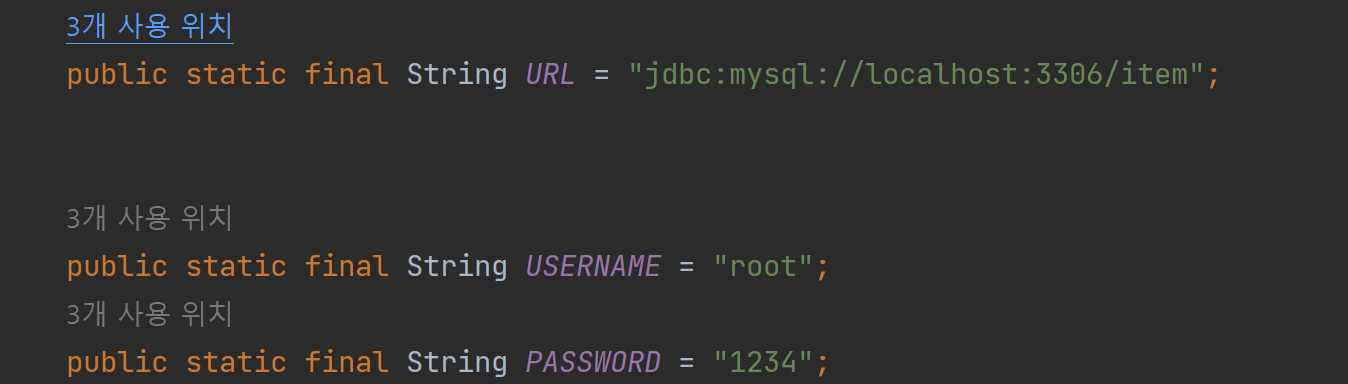
나의 DB경로는 이렇다.
나는 DB를 MySQL을 사용하기 때문에 MySQL을 참고 해주길 바란다.
hikariDataSource.setMaximumPoolSize(10);
그 후 DataSource는 커넥션 풀을 관리하기 위해서 사용한다고 말했듯이
나는 커넥션 풀 사이즈를 10으로 늘렸다. 그렇다면 Connection은 Pool에서 10개를 대기 중 으로 만드는 것 이다.
connection = hikariDataSource.getConnection();
그 후 getConnection을 통해서 Connection을 획득해서
return connection;
이렇게 반환 값으로 Connection을 반환 값으로 넣어줬다.
이렇게 얻은 DataSource로는 무엇을 할 수 있냐? 라고 한다면
DB연결 하기 위해선 대부분은 DataSource를 사용한다.
그렇기에 JPA 연결하기위한 EntityManager에 DataSource를 넣어 주거나

아니면 DB에 값들을 저장하기 위해서 Connection을 직접 메서드에 넣어줘 이 값들을 DB에 SQL을 보내기 위해
이렇게 DataSource로 사용 할 수 있다.
[🍓DataSource 인터페이스]
일단 기본적으로 DataSource는 URL , UserName , PassWord를 넣는 메서드가 없다
그렇기 때문에 넣을려고 한다면 HikariCp로 넣어줘야만 한다.
하지만 타입을 DataSource로 한다면 DataSource 인터페이스 자체에는
URL , UserName , PassWord를 넣는 메서드가 없다.
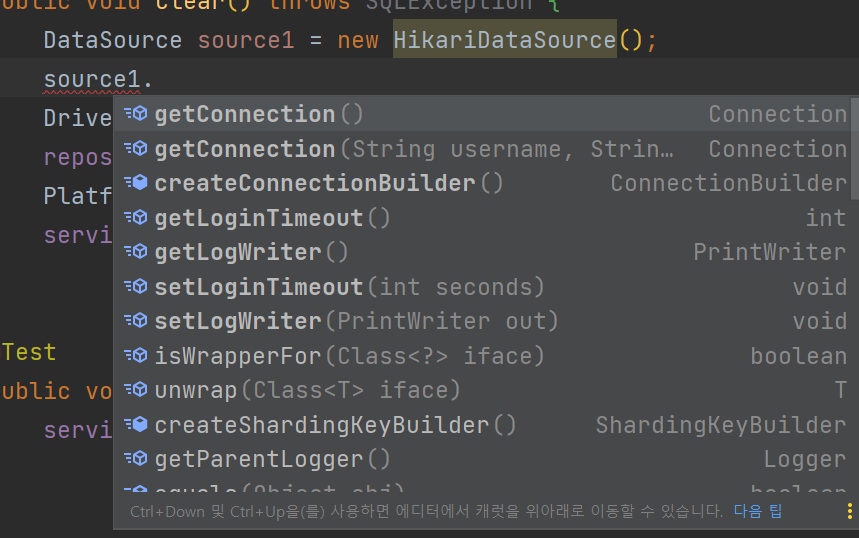
이런식으로 DataSource 인터페이스는 URL , UserName , PassWord를 넣는 메서드가 없다.
그렇다면 어떻게 해야할까?
가장 간단한 방법은 HikariCp를 사용해서 DB정보를 넣는 방법이 있다.
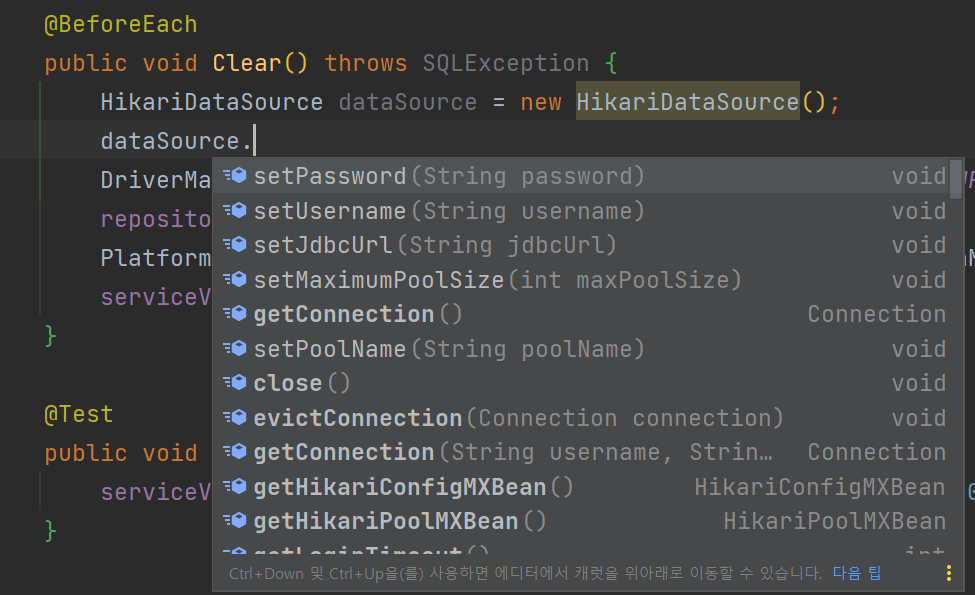

이렇게 HikariDataSource는 DataSource 를 구현받는 구현체 이기 때문에
DataSource의 인터페이스를 사용 할 수 있고
또한 타입이 HikariDataSource이기 때문에 클래스 안에 DB정보를 받는 메서드를 가지고 있다.

그렇기 때문에 HikariDataSource를 사용하거나 ..
DriverManagerDataSource source = new DriverManagerDataSource(URL,USERNAME,PASSWORD);
DriverManagerDataSource도 DataSource를 받는 구현체 이기 때문에 인터페이스를 적용 할 수 있다.
[스프링 부트의 DataSource]
이렇게 써보니까 큰 불편함을 느낀다.
저렇게 하나하나 일일이 언제 넣어줄 것 이며 static으로 일일이 불러오는 것도 힘든 일이다.
이러한 불편함을 없애기 위해 스프링은 자동화 기능을 제공 해준다.

이렇게 Properties에 URL , UserName , PassWord를 입력하면 자동으로 DataSource의 경로를
넣어준다. 그렇기 때문에
@RequiredArgsConstructor
@AutoWired
등으로 자동주입을 사용하면 스프링에서 자동으로 DataSource를 자동주입을 시켜준다.
그 후 필드에 DataSource를 자동주입을 받아서 사용하면 된다.
'[스프링 DB] > DataSource,JDBC' 카테고리의 다른 글
| [스프링 DB] JDBC란? JDBC 이해와 원리 (0) | 2023.06.05 |
|---|